Учёный решил провести кластеризацию некоторого множества звёзд по их расположению на карте звёздного неба. Кластер звёзд – это набор звёзд (точек) на графике, лежащий внутри прямоугольника высотой  и шириной
и шириной  . Каждая звезда обязательно принадлежит только одному из кластеров.
. Каждая звезда обязательно принадлежит только одному из кластеров.
Истинный центр кластера, или центроид, – это одна из звёзд на графике, сумма расстояний от которой до всех остальных звёзд кластера минимальна.
Под расстоянием понимается расстояние Евклида между двумя точками  и
и  на плоскости, которое вычисляется по формуле:
на плоскости, которое вычисляется по формуле:

Аномалиями назовём точки, находящиеся на расстоянии более одной условной единицы от точек кластеров. При расчётах аномалии учитывать не нужно.
В файле A хранятся данные о звёздах пяти кластеров, где  ,
,  для каждого кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата x, затем координата y. Значения даны в условных единицах. Известно, что количество звёзд не превышает 1600.
для каждого кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата x, затем координата y. Значения даны в условных единицах. Известно, что количество звёзд не превышает 1600.
В файле B хранятся данные о звёздах четырех кластеров, где  ,
,  для каждого кластера. Известно, что количество звёзд не превышает 21000. Структура хранения информации о звездах в файле B аналогична файлу А.
для каждого кластера. Известно, что количество звёзд не превышает 21000. Структура хранения информации о звездах в файле B аналогична файлу А.
Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа:  — среднее арифметическое абсцисс центров кластеров, и
— среднее арифметическое абсцисс центров кластеров, и  – среднее арифметическое ординат центров кластеров.
– среднее арифметическое ординат центров кластеров.
В ответе запишите четыре числа через пробел: сначала целую часть произведения  для файла А, затем
для файла А, затем  для файла А, далее целую часть произведения
для файла А, далее целую часть произведения  для файла Б и
для файла Б и  для файла Б.
для файла Б.
Возможные данные одного из файлов иллюстрированы графиком.
Внимание! График приведён в иллюстративных целях для произвольных значений, не имеющих отношения к заданию. Для выполнения задания используйте данные из прилагаемого файла.
Для начала визуально оценим данные в условии кластеры. Для этого откроем предложенные файлы в  , перейдем в раздел «Вставка
, перейдем в раздел «Вставка  Диаграммы
Диаграммы  Точечная».
Точечная».
Диаграмма для файла А имеет вид:
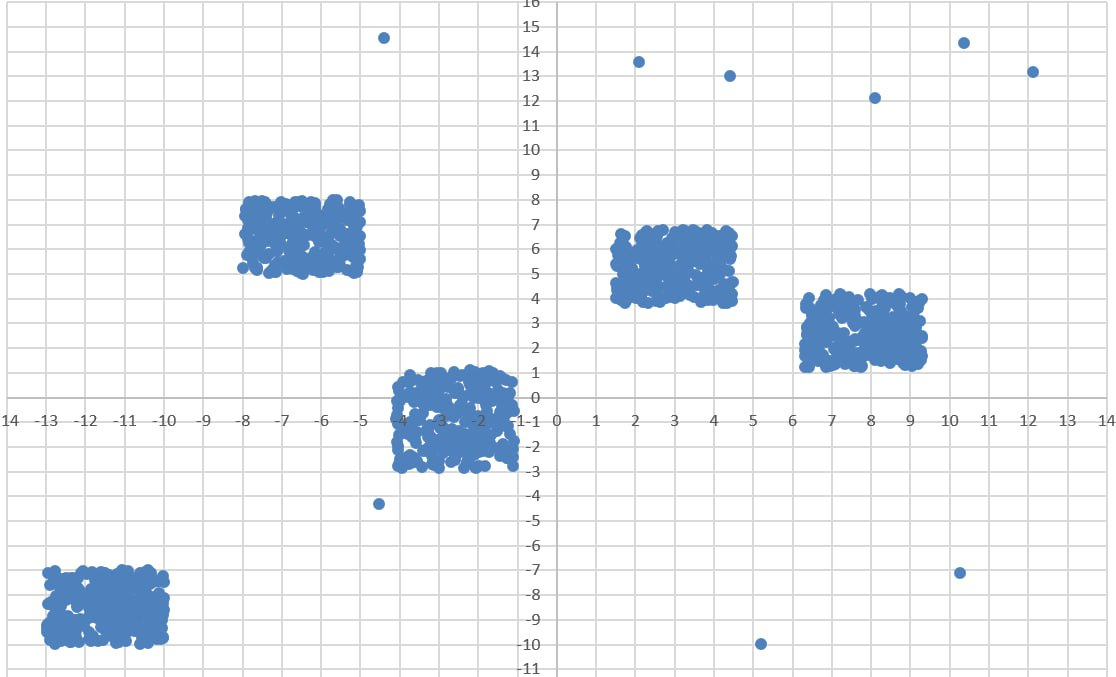
Рассмотрим интервалы, в которых лежит каждый кластер:
1) 
2) 
3) 
4) 
5) 
Код программы для файла А:
f = open(’4A.txt’)
n = f.readline()
a = [[] for i in range(5)]
for i in range(1508):
star = list(map(float, f.readline().replace(’,’, ’.’).split()))
if (-9 < star[0] < -4) and (4 < star[1] < 9):
a[0].append(star)
elif (1 < star[0] < 5) and (3 < star[1] < 8):
a[1].append(star)
elif (6 < star[0] < 10) and (0 < star[1] < 5):
a[2].append(star)
elif (-5 < star[0] < 0) and (-4 < star[1] < 2):
a[3].append(star)
elif (-14 < star[0] < -9) and (-11 < star[1] < -6):
a[4].append(star)
sum_x = sum_y = tx = ty = 0
for i in a:
mn = 100000050000
for j in i:
x1, y1 = j
sm = 0
for k in i:
x2, y2 = k
sm += ((x2-x1)**2 + (y2-y1)**2)**0.5
if sm < mn:
mn = sm
tx, ty = x1, y1
sum_x += tx
sum_y += ty
print(int(sum_x / 5 * 100))
print(int(sum_y / 5 * 100))
Диаграмма для файла Б имеет вид:
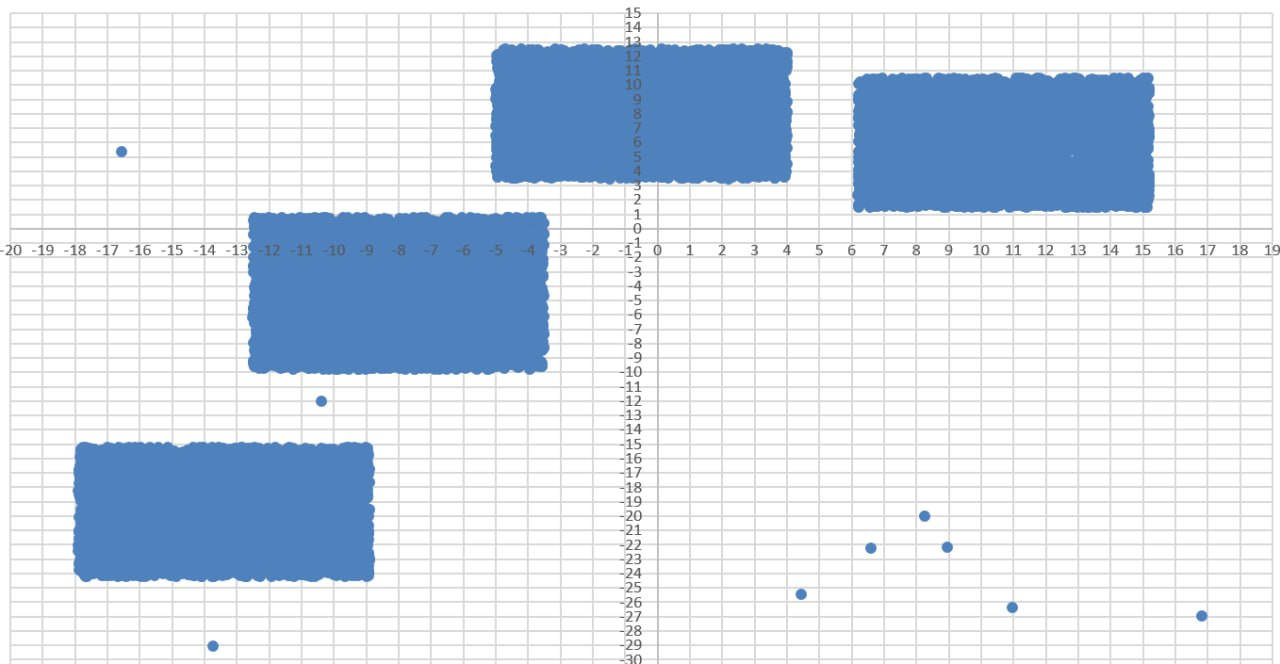
Рассмотрим интервалы, в которых лежит каждый кластер:
1) 
2) 
3) 4)

Код программы для файла Б:
f = open(’4B.txt’)
n = f.readline()
a = [[] for i in range(4)]
for i in range(18008):
star = list(map(float, f.readline().replace(’,’, ’.’).split()))
if (-19 < star[0] < -8) and (-26 < star[1] < -14):
a[0].append(star)
elif (-6 < star[0] < 5) and (2 < star[1] < 14):
a[1].append(star)
elif (star[0] > 5) and (star[1] > 0):
a[2].append(star)
elif (-14 < star[0] < -3) and (-11 < star[1] < 2):
a[3].append(star)
sum_x = sum_y = tx = ty = 0
for i in a:
mn = 100000050000
for j in i:
x1, y1 = j
sm = 0
for k in i:
x2, y2 = k
sm += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
if sm < mn:
mn = sm
tx, ty = x1, y1
sum_x += tx
sum_y += ty
print(int(sum_x / 4 * 100))
print(int(sum_y / 4 * 100))