Финес и Ферб, вдохновлённые летними каникулами, решили построить трёхмерную модель звёздного неба и провести кластеризацию звёзд. Кластер звёзд — это набор точек, где каждая звезда находится от хотя бы одной другой на расстоянии не более  условных единиц. Каждая звезда принадлежит только одному кластеру.
условных единиц. Каждая звезда принадлежит только одному кластеру.
Истинный центр кластера, или центроид, — это звезда, сумма расстояний от которой до всех остальных звёзд кластера минимальна.
Расстояние между точками  и
и  вычисляется по формуле:
вычисляется по формуле:

Аномалиями называются точки, расположенные более чем на одну условную единицу от всех точек кластеров. Аномалии в расчётах не учитываются.
В файле A хранятся данные о звёздах двух кластеров, где  для каждого кластера. В каждой строке записаны координаты звезды:
для каждого кластера. В каждой строке записаны координаты звезды:  ,
,  ,
,  . Значения — вещественные числа в условных единицах. Количество звёзд не превышает 1000.
. Значения — вещественные числа в условных единицах. Количество звёзд не превышает 1000.
В файле B хранятся данные о звёздах четырёх кластеров, где  для каждого кластера. Количество звёзд не превышает 5200. Структура данных аналогична файлу A.
для каждого кластера. Количество звёзд не превышает 5200. Структура данных аналогична файлу A.
Для каждого файла определите координаты центроида каждого кластера, затем вычислите  — квадрат произведения средних арифметических абсцисс, ординат и аппликат центроидов.
— квадрат произведения средних арифметических абсцисс, ординат и аппликат центроидов.
В ответе запишите два числа через пробел: сначала целую часть  для файла A, затем целую часть
для файла A, затем целую часть  для файла B.
для файла B.
Внимание! График приведён в иллюстративных целях и не относится к заданию. Используйте данные из прилагаемого файла.
Визуализируем данные, открыв файлы в  и построив точечные диаграммы через «Вставка
и построив точечные диаграммы через «Вставка  Диаграммы
Диаграммы  Точечная». Это покажет двухмерную проекцию кластеров на ось
Точечная». Это покажет двухмерную проекцию кластеров на ось  .
.
Диаграмма для файла A имеет вид:
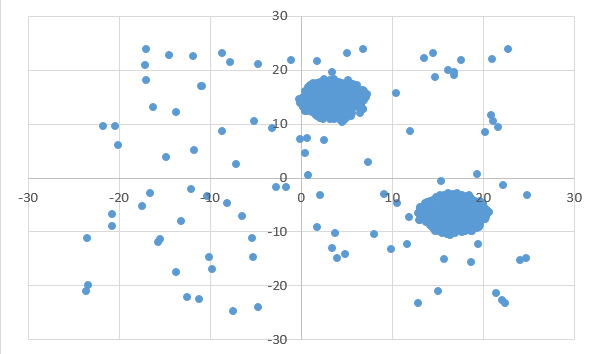
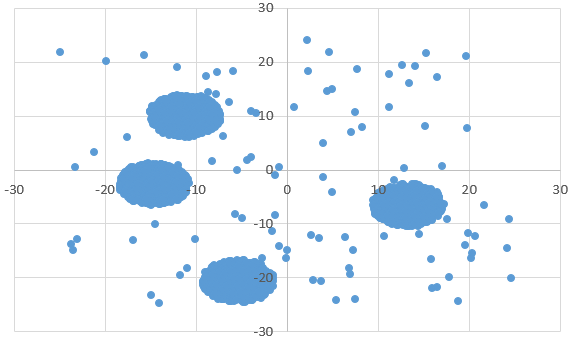
Диаграмма для файла B имеет вид:
Используем DBSCAN для кластеризации с заданными радиусами. Находим центроиды кластеров, минимизируя сумму расстояний, и вычисляем  на основе средних координат.
на основе средних координат.
Код для файла A:
from math import *
def dbscan(a, r):
cl = [] # Инициализируем список для хранения кластеров
while a: # Пока есть элементы в входном массиве ’a’
cl.append([a.pop(0)])
for i in cl[-1]: # Проходим по элементам последнего кластера
for j in a[:]:
if dist(i, j) <= r:
cl[-1].append(j) # Добавляем ’j’ в текущий кластер
a.remove(j) # Удаляем ’j’ из списка ’a’, чтобы не проверять его снова
return cl
f = open("5_A.txt")
a = [list(map(float, i.replace(",", ".").split())) for i in f]
cl = dbscan(a, 1)
cl_total = []
for i in cl:
if len(i) > 10: cl_total.append(i)
sum_x = sum_y = sum_z = 0
for cluster in cl_total:
tx = ty = tz = 0
mn = 10 ** 20
for centroid in cluster:
sm = 0
for star in cluster:
sm += dist(centroid, star)
if sm < mn:
mn = sm
tx, ty, tz = centroid[0], centroid[1], centroid[2]
sum_x += tx
sum_y += ty
sum_z += tz
print(int(((sum_x / 2 * sum_y / 2 * sum_z / 2) ** 2) / 4))
Код для файла B:
from math import *
def dbscan(a, r):
cl = [] # Инициализируем список для хранения кластеров
while a: # Пока есть элементы в входном массиве ’a’
cl.append([a.pop(0)])
for i in cl[-1]: # Проходим по элементам последнего кластера
for j in a[:]:
if dist(i, j) <= r:
cl[-1].append(j) # Добавляем ’j’ в текущий кластер
a.remove(j) # Удаляем ’j’ из списка ’a’, чтобы не проверять его снова
return cl
f = open("5_B.txt")
a = [list(map(float, i.replace(",", ".").split())) for i in f]
cl = dbscan(a, 0.7)
cl_total = []
for i in cl:
if len(i) > 10: cl_total.append(i)
sum_x = sum_y = sum_z = 0
for cluster in cl_total:
tx = ty = tz = 0
mn = 10 ** 20
for centroid in cluster:
sm = 0
for star in cluster:
sm += dist(centroid, star)
if sm < mn:
mn = sm
tx, ty, tz = centroid[0], centroid[1], centroid[2]
sum_x += tx
sum_y += ty
sum_z += tz
print(int(((sum_x / 4 * sum_y / 4 * sum_z / 4) ** 2) * 10))