Учёный решил провести кластеризацию некоторого множества звёзд по их расположению на карте звёздного неба. Кластер звёзд – это набор звёзд (точек) на графике, каждая из которых находится от хотя бы одной другой звезды на расстоянии не более  условных единиц. Каждая звезда обязательно принадлежит только одному из кластеров.
условных единиц. Каждая звезда обязательно принадлежит только одному из кластеров.
Тройная звездная система – это система, в которой три звезды попарно находятся на расстоянии не более  . При этом других звезд на расстоянии менее
. При этом других звезд на расстоянии менее  у этих трех звезд быть не должно.
у этих трех звезд быть не должно.
Под расстоянием понимается расстояние Евклида между двумя точками  и
и  на плоскости, которое вычисляется по формуле:
на плоскости, которое вычисляется по формуле:

Аномалиями назовём точки, находящиеся на расстоянии более одной условной единицы от точек кластеров. При расчётах аномалии учитывать не нужно.
В файле A хранятся данные о звёздах трех кластеров, где  ,
,  для каждого кластера. В каждой строке записана информация о расположении на карте одной звезды, а также её масса (в солнечных массах): сначала координата
для каждого кластера. В каждой строке записана информация о расположении на карте одной звезды, а также её масса (в солнечных массах): сначала координата  , затем координата
, затем координата  , затем масса
, затем масса  . Значения даны в условных единицах, которые представлены вещественными числами. Известно, что количество звёзд не превышает 11000.
. Значения даны в условных единицах, которые представлены вещественными числами. Известно, что количество звёзд не превышает 11000.
В файле Б хранятся данные о звёздах четырех кластеров, где  ,
,  для каждого кластера. Известно, что количество звёзд не превышает 31000. Структура хранения информации о звёздах в файле Б аналогична файлу А.
для каждого кластера. Известно, что количество звёзд не превышает 31000. Структура хранения информации о звёздах в файле Б аналогична файлу А.
Для каждого файла в каждом кластере найдите тройную звездную систему, состоящую из красного карлика (масса от 0.08 до 0.6 солнечных масс), желтого карлика (масса от 0.8 до 1.2 солнечных масс) и звезды с любой массой с максимальной площадью треугольника. Затем вычислите два числа:  — среднее арифметическое абсцисс найденных звезд, и
— среднее арифметическое абсцисс найденных звезд, и  – среднее арифметическое ординат найденных звезд.
– среднее арифметическое ординат найденных звезд.
В ответе запишите четыре числа через пробел: сначала целую часть произведения  для файла А, затем
для файла А, затем  для файла А, далее целую часть произведения
для файла А, далее целую часть произведения  для файла Б и
для файла Б и  для файла Б.
для файла Б.
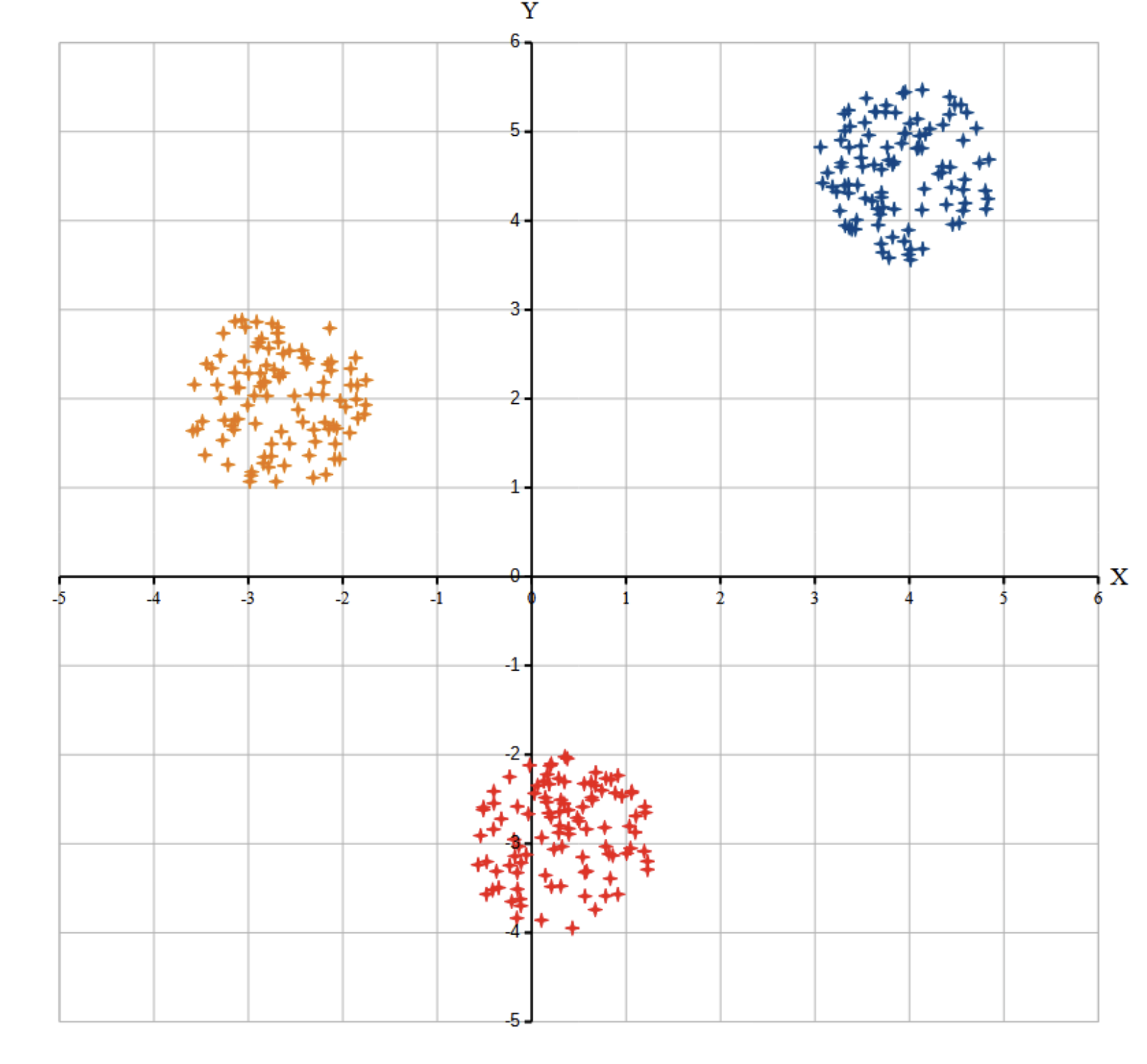
Возможные данные одного из файлов иллюстрированы графиком.
Внимание! График приведён в иллюстративных целях для произвольных значений, не имеющих отношения к заданию. Для выполнения задания используйте данные из прилагаемого файла.
Для начала визуально оценим данные в условии кластеры. Для этого откроем предложенные файлы в  , перейдем в раздел «Вставка
, перейдем в раздел «Вставка  Диаграммы
Диаграммы  Точечная».
Точечная».
Диаграмма для файла А имеет вид:
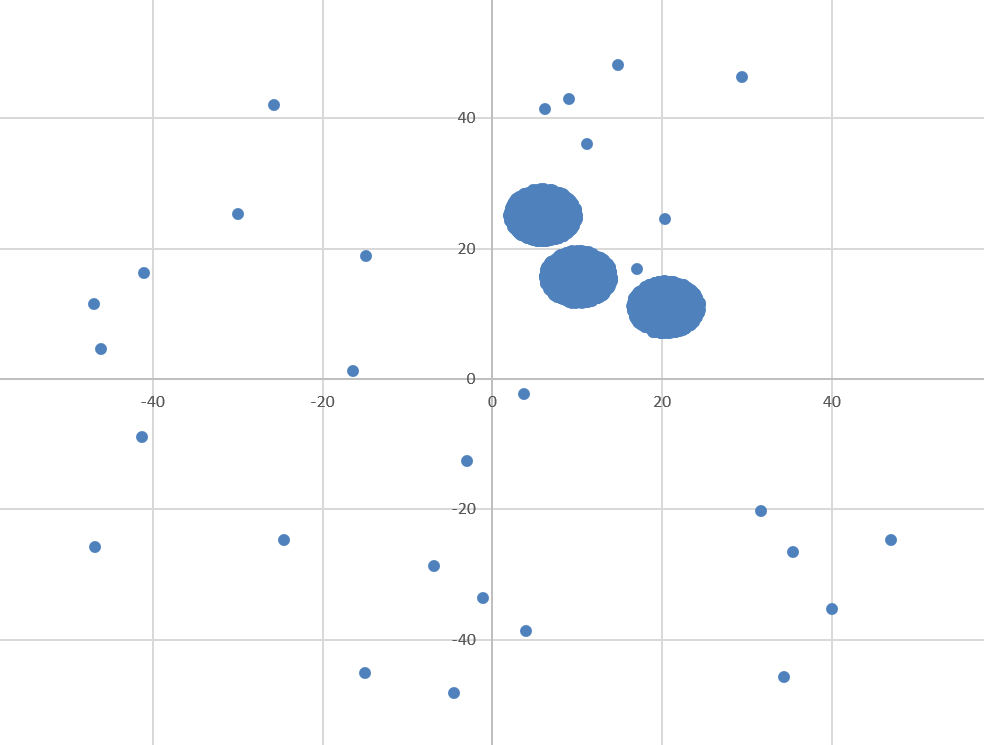
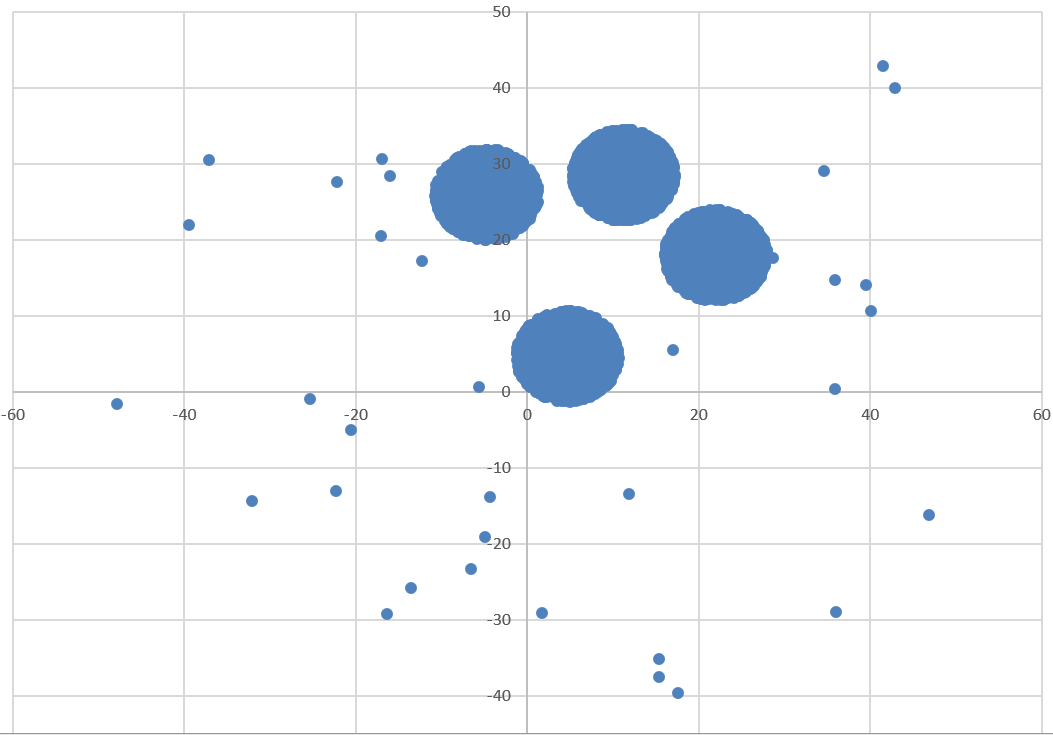
Диаграмма для файла Б имеет вид:
Для разделения звезд на кластеры будем использовать функцию dbscan.
Дальше основная идея решения будет заключаться в том, что мы будем проходить по каждой точке в 3 для файла А и 4 для файла Б найденных кластерах и с помощью того же метода dbscan для каждого кластера найти списки звезд, расстояние между которыми менее 0.08 для файла А и 0.05 для файла Б.
В каждом кластере нужно оставить только те списки, в которых количество звезд равно трем – то есть только тройные звездные системы. Также нужно проверить по массе звезд, чтобы в тройке были красный и желтый карлики.
В конце остается дело за малым: для каждой звездной системы в каждом кластере найти систему с максимальной площадью, а затем рассчитать среднее расстояние между всеми найденными тройками.
Программа для файла А:
from math import *
def dbscan(a, r):
cl = [] # Инициализируем список для хранения кластеров
while a: # Пока есть элементы в входном массиве ’a’
cl.append([a.pop(0)])
for i in cl[-1]: # Проходим по элементам последнего кластера
for j in a[:]:
x = [i[0], i[1]]
y = [j[0], j[1]]
if dist(x, y) <= r:
cl[-1].append(j) # Добавляем ’j’ в текущий кластер
a.remove(j) # Удаляем ’j’ из списка ’a’, чтобы не проверять его снова
return cl
f = open("2_A.txt")
s = f.readline()
a = [list(map(float, i.replace(",", ".").split())) for i in f]
cl = dbscan(a, 0.7) # Для файла А
cl_total = []
for i in cl:
if len(i) > 10: cl_total.append(i)
t = 0.08 # Для файла А
ans = []
for i in cl_total: # Проходим по каждому элементу в списке cl_total
found_star = dbscan(i, t) # Применяем алгоритм DBSCAN
tr_stars = [] # Список для тройных звездных систем
mn_starsys = [] # Список для хранения звездной системы с минимальной суммарной массой
# Проходим по каждому кластеру, найденному алгоритмом DBSCAN
for j in found_star:
if len(j) == 3: # Проверяем, состоит ли кластер из трех звезд
if ((0.08 <= j[0][2] <= 0.6 or 0.08 <= j[1][2] <= 0.6 or 0.08 <= j[2][2] <= 0.6)
and (0.8 <= j[0][2] <= 1.2 or 0.8 <= j[1][2] <= 1.2 or 0.8 <= j[2][2] <= 1.2)):
tr_stars.append(j)
mx_square = -100000
for j in tr_stars: # Проходим по всем найденным тройным системам
x = [j[0][0], j[0][1]]
y = [j[1][0], j[1][1]]
z = [j[2][0], j[2][1]]
d1 = dist(x, y)
d2 = dist(x, z)
d3 = dist(z, y)
half_per = (d1 + d2 + d3) / 2
if (half_per * (half_per - d1) * (half_per - d2) * (half_per - d3)) ** 0.5 > mx_square and d1 < t and d2 < t and d3 < t:
mx_square = (half_per * (half_per - d1) * (half_per - d2) * (half_per - d3)) ** 0.5 # Обновляем максимальную площадь
mn_starsys = j # Сохраняем текущую звездную систему
ans.append(mn_starsys)
res_X = 0
res_Y = 0
for i in ans:
res_X += (i[0][0] + i[1][0] + i[2][0])
res_Y += (i[0][1] + i[1][1] + i[2][1])
print(int(res_X / (3 * 3) * 1000)) # Для файла А
print(int(res_Y / (3 * 3) * 1000)) # Для файла А
Программа для файла Б:
from math import *
def dbscan(a, r):
cl = [] # Инициализируем список для хранения кластеров
while a: # Пока есть элементы в входном массиве ’a’
cl.append([a.pop(0)])
for i in cl[-1]: # Проходим по элементам последнего кластера
for j in a[:]:
x = [i[0], i[1]]
y = [j[0], j[1]]
if dist(x, y) <= r:
cl[-1].append(j) # Добавляем ’j’ в текущий кластер
a.remove(j) # Удаляем ’j’ из списка ’a’, чтобы не проверять его снова
return cl
f = open("2_B.txt")
s = f.readline()
a = [list(map(float, i.replace(",", ".").split())) for i in f]
cl = dbscan(a, 0.5) # Для файла Б
cl_total = []
for i in cl:
if len(i) > 10: cl_total.append(i)
t = 0.05 # Для файла Б
ans = []
for i in cl_total: # Проходим по каждому элементу в списке cl_total
found_star = dbscan(i, t) # Применяем алгоритм DBSCAN
tr_stars = [] # Список для тройных звездных систем
mn_starsys = [] # Список для хранения звездной системы с минимальной суммарной массой
# Проходим по каждому кластеру, найденному алгоритмом DBSCAN
for j in found_star:
if len(j) == 3: # Проверяем, состоит ли кластер из трех звезд
if ((0.08 <= j[0][2] <= 0.6 or 0.08 <= j[1][2] <= 0.6 or 0.08 <= j[2][2] <= 0.6)
and (0.8 <= j[0][2] <= 1.2 or 0.8 <= j[1][2] <= 1.2 or 0.8 <= j[2][2] <= 1.2)):
tr_stars.append(j)
mx_square = -100000
for j in tr_stars: # Проходим по всем найденным тройным системам
x = [j[0][0], j[0][1]]
y = [j[1][0], j[1][1]]
z = [j[2][0], j[2][1]]
d1 = dist(x, y)
d2 = dist(x, z)
d3 = dist(z, y)
half_per = (d1 + d2 + d3) / 2
if (half_per * (half_per - d1) * (half_per - d2) * (half_per - d3)) ** 0.5 > mx_square and d1 < t and d2 < t and d3 < t:
mx_square = (half_per * (half_per - d1) * (half_per - d2) * (half_per - d3)) ** 0.5 # Обновляем максимальную площадь
mn_starsys = j # Сохраняем текущую звездную систему
ans.append(mn_starsys)
res_X = 0
res_Y = 0
for i in ans:
res_X += (i[0][0] + i[1][0] + i[2][0])
res_Y += (i[0][1] + i[1][1] + i[2][1])
print(int(res_X / (4 * 3) * 1000)) # Для файла Б
print(int(res_Y / (4 * 3) * 1000)) # Для файла Б